Starframe devlog: Architecture
Edit history
- 2025-01-05: Added a note about new implementation
- 2025-11-26: Updated links from GitHub to Codeberg
I've spent a large portion of the past two years writing and rewriting the basic structures that describe a game and its content in Starframe (formerly known as MoleEngine). These are some notes on what I've done so far and what I've learned from it.
I'll start with some rambling about the nature of game engines and game objects before diving into rambling about the Entity-Component-System architecture and my efforts at implementing it. Finally, I'll ramble about my latest approach, which represents objects as a more general graph. There will be a lot of implementation details and code examples that are specific to the Rust language, but also many ideas that can be applied elsewhere.
2025 note: None of the structures covered here are being used in Starframe anymore. In fact, I've given up the idea of making my own entity system and adopted hecs (a nice off-the-shelf ECS) instead. The Component Graph structure detailed in this post was an interesting experiment, but had some tradeoffs that made it cumbersome to use. With sufficient effort it could probably be developed into a viable alternative to ECS, but I think something like flecs with its relationships system strikes a better balance.
Intro: Engines and objects§
When I started this project I had this vague idea that it should follow an architecture of some kind. After some thought and experience I realized I didn't know what that even meant or if it made any sense. Let me take a moment to ponder about it here.
First of all, it's difficult to define exactly what a game engine is in the first place. The best-known ones sold as products of their own, like Unity, Unreal and Godot, are huge suites of reusable tools for every aspect of game production. Everything from physics libraries to graphical editing tools is considered part of the package that is the engine. On the other hand, many games have tools and background libraries built specifically for them. In these cases the separation between "engine" and "gameplay" code can get very blurry.
So there isn't really a generally agreed upon way to build an engine, nor a well-defined architecture of such a thing. However, there is one concept at the heart of an engine that almost every tool operates on in some way, and that is the game object, also known as the entity. I'll speak about game objects here to create some separation between this concept and the specific idea of an Entity in the Entity-Component-System model.
Game objects are another thing whose definition is quite hard to nail down. If you'll forgive the hand-waving, they're things that exist in a game world in a similar, but not quite the same, way to real objects in the real world. Things with a function and an identity (in the metaphysical sense, not the mathematical).
In order to have any purpose or behavior, game objects need to have some data associated with them. These associations can be implemented in many ways, and any tool or system that touches game objects (i.e. most of them) needs to be able to follow them. Well, either that or you need additional compatibility code converting things to whatever formats each system wants, which is the only option if you want your systems to be usable outside of the engine they were made for. A large part of the Amethyst game engine's job, for instance, is to glue various libraries (many of them also developed by the Amethyst team, but intentionally made independent of the engine) into their entity system of choice.
Anyway, this is where architecture suddenly becomes crucial in a fully integrated engine like mine – almost every higher-level system depends on how you compose game objects. So in a sense, you could call the architecture of game objects the fundamental architecture of a game engine. This is why I've spent so much time thinking about this and doing it over and over. I don't want to build too big of a pile of code on top of my object model until I'm happy with it, because every time I redo it I have to update large parts of everything else.
If I actually wanted to make games I should just use a library made by smarter people than me instead of spending years figuring this stuff out for myself, but I guess I'm finding this more fun ¯\_(ツ)_/¯
Building up§
Before we get to the things I've been building, let's establish a starting point that we can compare to. I've made a thing that's considerably complicated, and there are reasons why I want to have that thing, but you can boil the same concept down to a very simple thing indeed.
We already have a type system provided by our programming language, why not just use it to represent our objects?
struct Goblin {
position: Vector2<f32>,
attack_power: u32,
health: u32,
catchphrase: String,
has_a_gun: bool,
}
In languages with support for sum types (a.k.a. tagged unions or fat enums) you can even build a single all-encompassing object type (or multiple some-encompassing ones) that can be queried for components in a similar fashion to the more complicated systems we're about to discuss.
enum GameObject {
Player(Player),
Goblin(Goblin),
Projectile(Projectile),
Decoration(Decoration),
// ...
}
impl GameObject {
pub fn get_rigid_body(&self) -> Option<&RigidBody> {
match self {
GameObject::Projectile(p) => Some(p.body),
GameObject::Decoration(_) => None,
// ... you get the idea
}
}
pub fn get_position(&self) -> Option<&Vector2<f32>> { /* ... */ }
pub fn get_sprite(&self) -> Option<&Sprite> { /* ... */ }
}
(In real life I would probably implement these getters as traits and use them to make code generic to the concrete object type, but that's not relevant to the example)
Depending on how many object types you have, how large your team is and how much of a concern performance is, this may well be flexible enough to support an entire game. Check out this post by Mason Remaley for a more detailed description of such a system, as implemented in the game Way of Rhea. This approach is dead simple and has some genuine advantages over other models (simplicity in itself is a big one!), but is not quite as efficient as we might like. We'll talk about why in a minute.
Attempt 1: Generic ECS§
Entity-Component-System, or ECS for short, seems (to my limited perspective)
to be a de-facto standard in most of the game dev world at the moment.
There are various Rust crates implementing it, such as specs, legion, and hecs.
At the time I started, specs was the big ECS crate everyone was using, I saw this popular talk by Catherine West,
and was naturally led to look into the specs source as my primary reference.
So what is it?
ECS takes the struct from our initial example, gives it an identifier, rips all its fields out and distributes them into what are essentially database tables where they can be looked up with the identifier. The identifier is called the Entity, and the fields are Components. Game logic can select entities that have a certain set of components and ignore the rest. Functions that do this are called Systems.
Here's how I picture the difference in my head. Imagine different colors are different component types.
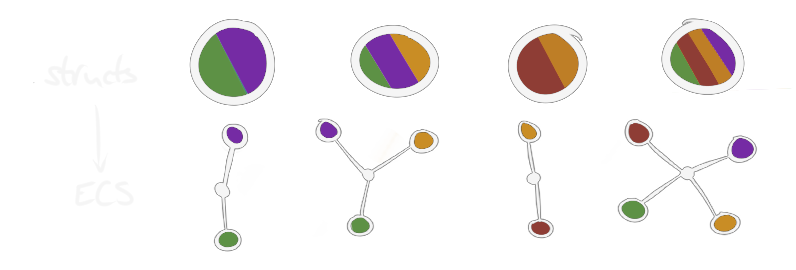
This improves performance by grouping data in memory more efficiently than those big everything-structs from earlier. To put it briefly, memory lookups are extremely slow, and processors do best when they get to go from one memory location to the one right next to it and repeat. This optimization is accomplished using caches of very fast memory close to the processor. In our big structs, most fields are irrelevant to most operations, but they still take up space in the cache all the time. On the other hand, ECS "tables" only have one type of thing each, so we can pick and choose what to pull into the cache by completely ignoring the tables we don't need.
The other benefits of this pattern stem from its nature as a dynamic type system, as do many of its flaws. When using structs we were defining types in Rust's static type system, which lets us use the compiler to verify that our objects are well-formed, but requires a programmer to write every object type the game supports. On the other hand, in ECS, all our types are defined at runtime by inserting components into tables. No programming is needed to create new types of object or to wire them into the game logic, but we get no static analysis to help catch errors. An interesting consequence is that an object can change its type at runtime — a classic example is an RPG character getting status effects added and removed dynamically as components.
My implementation
At this point I was still wrapping my head around what an ECS even is, and I started by more or less just copying what specs did.
I had a top-level manager called Space that gave out entity IDs, kept track of alive entities with a BitSet from the hibitset crate,
and stored all the component tables in an AnyMap from the anymap crate.
Tables were inside RwLocks to allow accessing many in parallel.
They also had their own BitSets to keep track of entities using them,
and queries used boolean operations on these to find the entities that had the components they were looking for.
I had different types of Storage for my component tables that would be selected by the user based on how common the component was —
VecStorage when almost every object has it, DenseVecStorage when it's common but not ubiquitous, HashMapStorage when it's rare,
and NullStorage when it's a zero-sized tag component.
Object IDs contained a generation index that allowed them to be deleted and overwritten with new things
in a way that invalidated any old components still hanging around.
Where things diverge a little from specs is in the queries that Systems use to select their desired component sets.
This was in some part because I didn't really care for the tuple-based interface in specs, but mostly because I didn't fully understand how it worked.
I wrote a rather long procedural macro that generated query implementations for structs of references (plus some special fields with special annotations)
like this one from my physics module:
#[derive(ComponentQuery)]
pub struct RigidBodyQuery<'a> {
#[id]
id: crate::ecs::IdType,
tr: &'a mut crate::util::Transform,
body: &'a mut crate::physics::RigidBody,
}
Running this query through a Space would return a slice &mut [RigidBodyQuery] where each item in the slice represented one entity.
I still think this is a neat interface, but the macro ended up so large it was quite hard to maintain.
Additional concepts I added from outside the realm of specs were Recipes and Pools.
A Recipe is similar to the idea of a prefab in most game engines.
It's a simple struct that knows how to turn itself into an entity, and with some macros around it,
also knows how to read itself from a file using serde.
Whereas prefabs are essentially prototypes defining all components of an entity,
customized on a per-object basis by changing the components' values,
these are more like constructor functions that take some parameters and produce entities out of them.
Here's what their definitions looked like.
If you're wondering about the recipes! macro (which I don't use anymore because it made people wonder),
it simply creates an enum with the given types as its variants, plus a bit more magic that was later deemed unnecessary.
With these I was able to read scenes from RON files like this:
[
Player ((
transform: ( position: (0, 0) ),
)),
DynamicBlock ((
width: 1, height: 0.8, transform: ( position: (1, -1.5) ),
)),
StaticBlock ((
width: 8, height: 0.2, transform: ( rotation: Deg(45) ),
)),
]
I still use more or less the same recipe system today. It's a concise but human-readable way to express scenes and helps a lot when a text file is the only level editor I have.
A Pool is an optimization for types of objects that are frequently spawned and deleted, such as bullets or other projectiles in an action game.
What it does is preallocate and take control of entity slots so that entities it manages are always placed in those slots.
The benefit of this is twofold — firstly, it prevents memory fragmentation from objects getting deleted and respawned far away in memory.
(In my understading this isn't actually an issue in an archetypal ECS which does some tricks to organize things automatically,
but I didn't even know those were a thing at this point.)
Secondly, it lets you limit the number of instances of an object type that can exist at one time,
preventing them from taking up more memory than your budget allows.
This was especially important in this implementation because my Spaces had a maximum capacity and weren't growable
after being created.
The last revision of source code with this implementation can be found here.
Attempt 2: Decentralized ECS§
I kept most of the first implementation for this one. Spaces, Storages, Pools, the whole gang was still around,
but the way I stored and queried my component tables was very different.
AnyMaps are cool and all, but they limit the compile-time checks you can do for things you put inside them.
What if I let the user define their own structs with the tables they want?
This way I could make better use of Rust's type system and, more importantly, borrow checker to hand out references instead
of locking things at runtime.
However, the central Space was still necessary, and if possible, I'd still like to force every table to be connected to it somehow
to prevent mixing tables from different Spaces and causing errors.
What I ended up doing was to let the user put anything they wanted in one field of Space, but restrict how and when they could access it.
Here's what the types looked like from the perspective of a game:
pub type MainSpace = Space<MainSpaceFeatures>;
pub struct MainSpaceFeatures {
transform: sf::core::TransformFeature,
shape: sf::graphics::ShapeFeature,
physics: sf::physics::PhysicsFeature,
player: player::PlayerController,
camera: sf::graphics::camera::MouseDragCamera,
}
All the types ending in Feature contain component tables.
Many of them also have game logic, so you could call them Systems in the ECS sense while also being parts of the data structure itself.
This is why I'm calling this thing "decentralized" — the data structure is scattered across a variety of types.
Here's how you'd access the MainSpaceFeatures in an update loop:
// simplified from examples/testgame/main.rs
space.tick(|features, iter_seed, _| {
features.player.tick(
iter_seed,
&game.input,
&mut features.transform,
&mut features.physics,
cmd_queue
);
let grav = forcefield::Gravity(Vec2::new(0.0, -9.81));
features.physics.tick(
iter_seed,
&mut features.transform,
dt,
Some(&grav),
);
});
A nice thing about these interfaces is that they explicitly tell you what other Features/tables they depend on, so you must have everything around to be able to call them at all (as opposed to earlier where systems looked things up on their own using the macro-generated queries). Running many of these in parallel should also be easy, safe and lock-free with Rust borrow-checking the references, although I never actually did this.
You may have noticed the iter_seed here, which leads us to the new query system.
As mentioned, the macro-generated queries were gone; they couldn't exist without the ability to look up a table by its type.
I needed something a little less automagical, which I wanted for maintainability's sake anyway.
After some wrestling with generics and closures, I managed to produce a set of iterator combinators that looked like this:
// simplified from src/physics/mod.rs
let mut iter = iter_seed
.overlay(self.bodies.iter_mut()) // `and` but hides previous items from the return type
.and(self.colliders.iter())
.and(transforms.iter_mut())
.with_ids()
.into_iter();
for (((body, coll), tr), id) in iter {
// do stuff...
}
The IterSeed is handed out by a Space, and produces a () for every entity that is alive.
You have to start with this. From there on you get various boolean operations to add parts to the query,
filtering out entities that don't fit the mold.
and is by far the most useful one, but things like not and or are also possible.
For those interested, the code for these is here.
Aside from the ugly nested tuples, which are fairly easily dealt with by one pattern match,
I was really happy with the expressiveness and lack of macros in this.
Aside from some newfound awkwardness in the Space API, overall I felt like all these things were improvements over the original.
The last revision of source code with this implementation can be found here.
Attempt 3: Graph§
Pretty much immediately after getting the previous implementation into a usable state I came across a crate called froggy, which sparked my imagination right away. It calls itself a Component Graph System because it connects components directly to each other without an Entity at the center. This is achieved with reference-counted pointers that are contained in the components themselves, which might look something like this:
struct RigidBody {
transform: Pointer<Transform>,
collider: Pointer<Collider>,
mass: Mass,
}
By nesting types that contain Pointers you can create all sorts of interesting hierarchies. These can be interpreted as directed graphs, hence the name.
Incidentally, this ends up looking a lot like the simple struct approach we started with,
but with custom "allocators" called Storages to arrange the data more efficiently in memory
and garbage collection to remove things that nobody needs anymore.
For a while I contemplated just using froggy and ditching my own entity system altogether.
I had some trouble imagining how I'd go about things like destroying an object on collision,
which would require going upwards in the hierarchy from the rigid body component where the collision occurred.
I don't doubt that this is a solvable problem with froggy, but this gave me a new idea:
what if I took the graph out of the components and made it an actual graph data structure?
This would open up many new algorithms and ways to move from one component to another,
at the cost of some extra memory for the graph and the loss of statically typed hierarchies.
Off I went to try this and see if it made any actual sense.
The data structures part of this is pretty simple. I have a central Graph to store edges and some node metadata,
and Layers for concrete storage of components, similar to froggy's Storages.
Layers always store their contents in a Vec; no need for any other storage types.
You register Layers with the Graph and it generates a Vec of edges between it and every other registered Layer,
represented as indices into the other Layer's storage.
You build a graph in a similar way to the "features" from my second ECS attempt, by defining a custom type:
pub struct MyGraph {
graph: Graph,
l_transform: Layer<Transform>,
l_collider: Layer<Collider>,
l_body: Layer<RigidBody>,
// etc.
}
impl MyGraph {
pub fn new() -> Self {
let mut graph = sf::graph::Graph::new();
let l_transform = graph.create_layer();
let l_collider = graph.create_layer();
let l_body = graph.create_layer();
MyGraph {
graph,
l_transform,
l_collider,
l_body,
}
}
}
Then insert components and connect them like this:
let g = MyGraph::new();
let tr_node = g.l_transform.insert(Transform::new(..), &mut g.graph);
let coll_node = g.l_collider.insert(Collider::new(..), &mut g.graph);
let body_node = g.l_body.insert(RigidBody::new(..), &mut g.graph);
g.graph.connect(&tr_node, &body_node); // edge both ways, tr_node -> body_node and body_node -> tr_node
g.graph.connect(&body_node, &coll_node);
g.graph.connect_oneway(&tr_node, &coll_node); // edge only from tr_node -> coll_node
When iterating on components, instead of selecting sets of them like in ECS, the equivalent here is selecting specific patterns in the graph, which is rather straightforward:
// match the pattern `Transform <-- RigidBody --> Collider`:
for mut body in g.l_body.iter_mut(&g.graph) {
let tr = match g.graph.get_neighbor(&body, &g.l_transform) {
Some(tr) => tr,
None => continue,
};
let coll = match graph.get_neighbor(&body, &g.l_collider) {
Some(c) => c,
None => continue,
};
// ...do stuff with `body`, `tr` and `coll`!
}
// note: you can do the same thing in fewer words by using `filter_map` on the iterator,
// but I felt like this one got the point across better
Aside from having to carry the central Graph around everywhere, I think this is pretty simple and neat.
However, things get a little more funky when we start wanting to delete things.
We need to figure out what it means for a collection of nodes and edges to be one object.
I'm going to need some pictures for this.
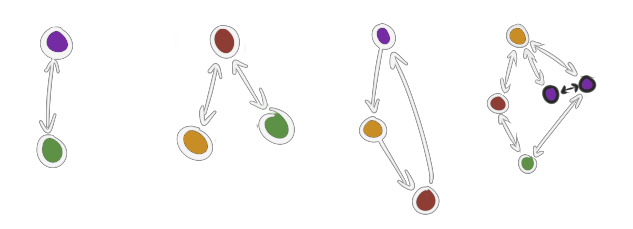
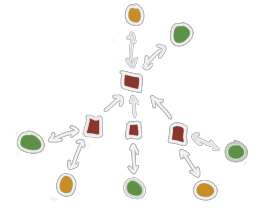
Imagine these are four different objects. Different-colored nodes are different types of components. What the types actually are doesn't matter, this is just about how you can connect them.
A typical object (as pictured above) still looks like the kind of object you can model with ECS, in the sense that every component belongs to this object only. Objects like this are straightforward enough to identify — simply collect every edge and node you can find by following edges around, and that collection is your object. To delete it we could just get rid of all the edges and nodes we found.
When we wander into the realm of patterns that are unique to this graph model, things get a little weird. Consider this scenario:
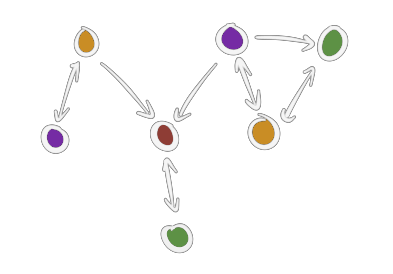
If we start deleting nodes on the left of the red node, everything on its right will remain untouched because there's no arrow that would take us to them, and vice versa. The red node is shared between two different objects. The problem is that the naive algorithm described above would delete the red and green node in both cases, stealing away some functionality from an unrelated object.
To identify situations like this I borrowed another idea from froggy, namely reference counting.
Every node now knows how many edges are pointing towards it.
With this information we're now armed to deal with this problem. I still run the same algorithm from earlier to find every edge and node I have a route to, but this time count the number of edges traversed leading to each node, then traverse again and compare this to the node's stored reference count. If they're equal, all edges were found and we can delete them. If not, we have identified a shared component and stop traversing in that direction.
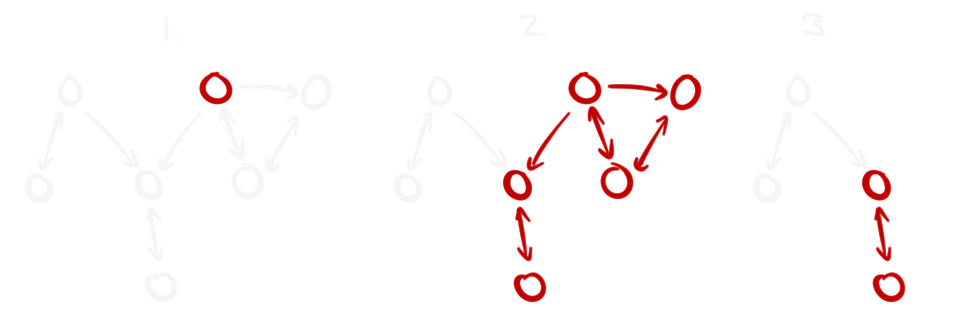
If we start on the node marked with red in step 1 and traverse every edge we find, we get the collection marked with red in step 2. The node at the center has more references to it than we found, so we stop deleting things there. The final step shows the end result.
Clearly this is not nearly as fast as deleting an object in a simpler model, but this accounts for such a small fraction of each frame of simulation I'm just not going to worry about it.
Building more complex hierarchies in this framework requires some thinking. Am I going to delete instances of this? If so, what will the deletion algorithm do if I start it on node X? Consider this pattern of Unity-style hierarchical transforms:
Here we have one object with several others as its "children" which transform in its local space (the red squares represent the transform components). To determine the world-space location of a child we connect its transform to the parent's. If we delete any of the children here, it'll work as expected and just delete the child's components, unless it's the only child left. Then the parent will be deleted as well. If we delete the parent before the children, all its nodes except the transform will be deleted. We could add edges pointing from the parent to the children, in which case the entire hierarchy would be deleted regardless of where you start.
These interactions are probably not exactly what you'd want or expect. For further control I'm going to need some kind of a "weak edge" mechanism (analogous to froggy's weak pointers) where certain edges won't be followed by the deletion algorithm. I haven't explored this properly yet. On the other hand, most objects aren't ever deleted so you can often just ignore these rules and make whatever works. I have to admit this is a lot of baggage attached to the improved flexibility over froggy, which may or may not be worth it.
Technically, the deletion algorithm only deletes edges. Any node whose reference count reaches zero in this process is implicitly considered deleted. Many parts of my code depend on nodes never changing positions, so I can't put anything else in the slots left behind by deleted nodes and therefore can't keep my storages perfectly packed. Deleted nodes become holes. Instead, I push their positions into a queue from which they will be picked up and reused by future nodes. Additionally, because node identifiers can live anywhere in the program, I store a generation index as part of said identifier that's incremented on delete. Nodes are only the same if both their position and their generation is the same.
That's about it for interesting parts of the current state of this thing. I don't yet know if it's actually any good but I'm having fun playing with it. I'll write more about this once I've had the time to come up with some interesting patterns and figure out if I like it better than ECS or not. Until then, I'll leave you with some random ideas and a quick recap.
Some random ideas§
I've been playing a lot of Elasto Mania lately, which made me think about how I would go about putting the player bike from it into my graph. It's got a lot of parts — the wheels with a collider and sprite each, the chassis of the bike and the rider's body parts with sprites plus a collider for his head, some spring constraints keeping the wheels in place, and an event listener of some kind that reacts to the head colliding with terrain. I'm not going to draw it because it would be massive, but I think all these things could be connected in the graph as one big "object", which might be cool maybe.
As for the event listener, I've already implemented an EventSink component that subscribes
to events by simply connecting to components that produce them.
For instance, to listen to collision events, connect an EventSink to a RigidBody in the graph.
I think it's neat.
Elasto Mania also has terrain constructed out of closed loops of line segments, which could be graphified as a loop where nodes are individual vertices.
Connect a Transform somewhere and you have a movable polygonal collider instead. This would allow an arbitrary number of vertices per collider / terrain loop while staying perfectly packed in memory.
A quick recap§
This was a post about game engines, game objects and ways to compose them. After some quick philosophy we started by representing objects directly with programming language constructs, which is nice, simple and statically typed (language permitting) but creates an inefficient memory layout and some moderately annoying boilerplate code. We then looked at Entity-Component-System, a database-like approach that arranges memory nicely and allows things to change their type at runtime, and my two attempts at implementing it. Finally, we looked at a novel graph-based approach that creates some interesting new patterns (and some interesting new problems).
I realize this was a little long-winded, and to be honest I mostly wrote it just to get myself thinking, but I hope you found it interesting. If you read this far I'm going to assume that was the case.